6 Thành Phần Của Context Engineering
Dưới đây là phép tính sơ bộ về những yếu tố quyết định chất lượng đầu ra của ứng dụng AI:
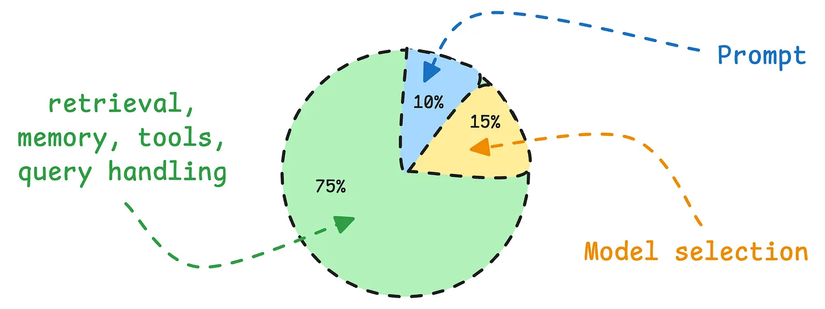
- Lựa chọn mô hình: 15%
- Prompt: 10%
- Mọi thứ còn lại (truy xuất, bộ nhớ, công cụ, xử lý truy vấn): 75%
Chúng ta đã chứng kiến rất nhiều đội ngũ dành quá nhiều thời gian và công sức cho 25% không quan trọng, trong khi vấn đề thực sự nằm ở phần còn lại.
Đó chính là lý do vì sao Context Engineering đã lặng lẽ trở thành kỹ năng quan trọng nhất trong lĩnh vực kỹ thuật AI hiện nay.
Context Engineering là nghệ thuật đưa đúng thông tin đến mô hình vào đúng thời điểm và dưới đúng định dạng.
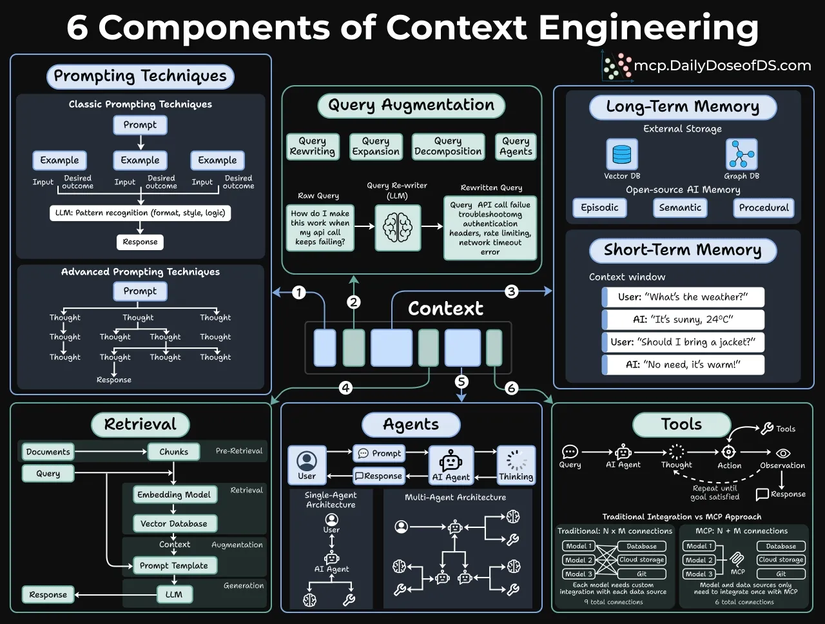
Nó bao gồm 6 thành phần cốt lõi, như được minh họa trong hình ảnh dưới đây:
1. Kỹ Thuật Prompting
Đây là nơi hầu hết mọi người dừng lại. Tuy nhiên, ngay cả trong phần này cũng có nhiều chiều sâu hơn những gì mọi người thường nghĩ.
Prompting truyền thống dựa trên việc nhận diện mẫu. Bạn cung cấp cho mô hình các ví dụ, và mô hình sẽ học được định dạng, phong cách cũng như logic mà bạn mong muốn. Few-shot prompting vẫn mang lại hiệu quả tuyệt vời cho các nhiệm vụ có cấu trúc.
Nhưng prompting nâng cao mới thực sự thú vị.

Các kỹ thuật như Chain-of-Thought prompting cho phép mô hình có không gian suy nghĩ. Thay vì yêu cầu trả lời ngay lập tức, bạn hướng dẫn mô hình suy luận từng bước một. Chỉ với thay đổi đơn giản này, độ chính xác trên các vấn đề phức tạp đã tăng lên đáng kể.
2. Tăng Cường Truy Vấn (Query Augmentation)
Người dùng thường viết truy vấn rất ngắn gọn và mơ hồ.
Một câu hỏi kiểu “Làm thế nào để khắc phục khi API call của tôi liên tục thất bại?” gần như vô dụng đối với hệ thống truy xuất.
Tăng cường truy vấn giải quyết vấn đề này bằng nhiều kỹ thuật:
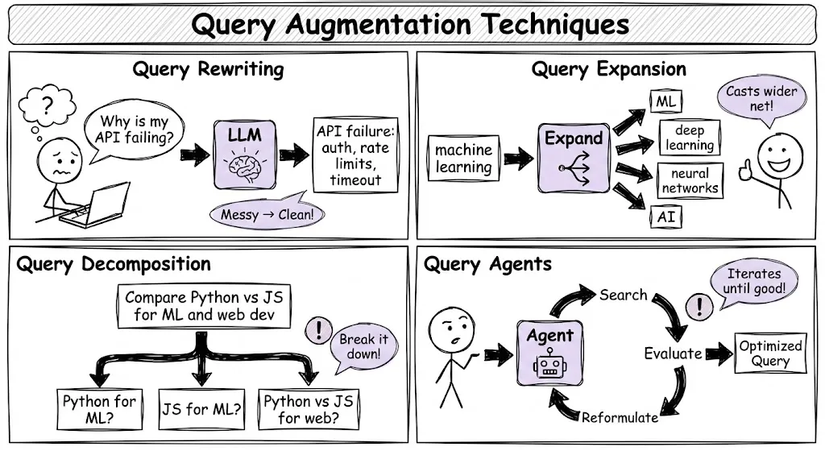
- Viết lại truy vấn (Query Rewriting): Một LLM sẽ biến đổi câu hỏi mơ hồ thành phiên bản rõ ràng hơn.
- Mở rộng truy vấn (Query Expansion): Thêm các từ đồng nghĩa và khái niệm liên quan để mở rộng phạm vi tìm kiếm.
- Phân tích truy vấn (Query Decomposition): Chia nhỏ câu hỏi phức tạp thành nhiều câu hỏi phụ độc lập.
- Agent truy vấn: Sử dụng agent để linh hoạt quyết định cách viết lại truy vấn dựa trên kết quả ban đầu.
3. Bộ Nhớ Dài Hạn (Long-Term Memory)
Giả sử một agent vừa có cuộc trò chuyện tuyệt vời với người dùng – người dùng đã chia sẻ sở thích, ngữ cảnh và lịch sử. Nhưng khi phiên kết thúc, mọi thứ biến mất.
Bộ nhớ dài hạn khắc phục hạn chế này bằng cách lưu trữ bên ngoài:
- Cơ sở dữ liệu vector: Lưu embedding của các tương tác trước để tìm kiếm ngữ nghĩa.
- Cơ sở dữ liệu đồ thị: Lưu trữ cuộc trò chuyện dưới dạng mối quan hệ và thực thể.
Có ba loại bộ nhớ quan trọng:
- Bộ nhớ theo sự kiện (Episodic memory) – ghi nhận các sự kiện cụ thể.
- Bộ nhớ ngữ nghĩa (Semantic memory) – lưu trữ thông tin chung về người dùng.
- Bộ nhớ thủ tục (Procedural memory) – ghi nhớ cách người dùng thích thực hiện công việc.
Các công cụ mã nguồn mở như Cognee giúp triển khai bộ nhớ dài hạn trở nên dễ dàng mà không cần xây dựng từ đầu.
4. Bộ Nhớ Ngắn Hạn (Short-Term Memory)
Bộ nhớ ngắn hạn chính là lịch sử cuộc trò chuyện. Nghe có vẻ đơn giản, nhưng đây lại là phần thường bị quản lý kém nhất.
Các sai lầm phổ biến:
- Nhồi nhét quá nhiều thông tin vào cửa sổ ngữ cảnh (nhiễu lấn át tín hiệu quan trọng).
- Cung cấp quá ít thông tin (mô hình thiếu dữ liệu cần thiết).
- Sắp xếp thứ tự kém (thông tin quan trọng bị chôn sâu ở cuối).
- Không có chiến lược tóm tắt cho các cuộc trò chuyện dài.
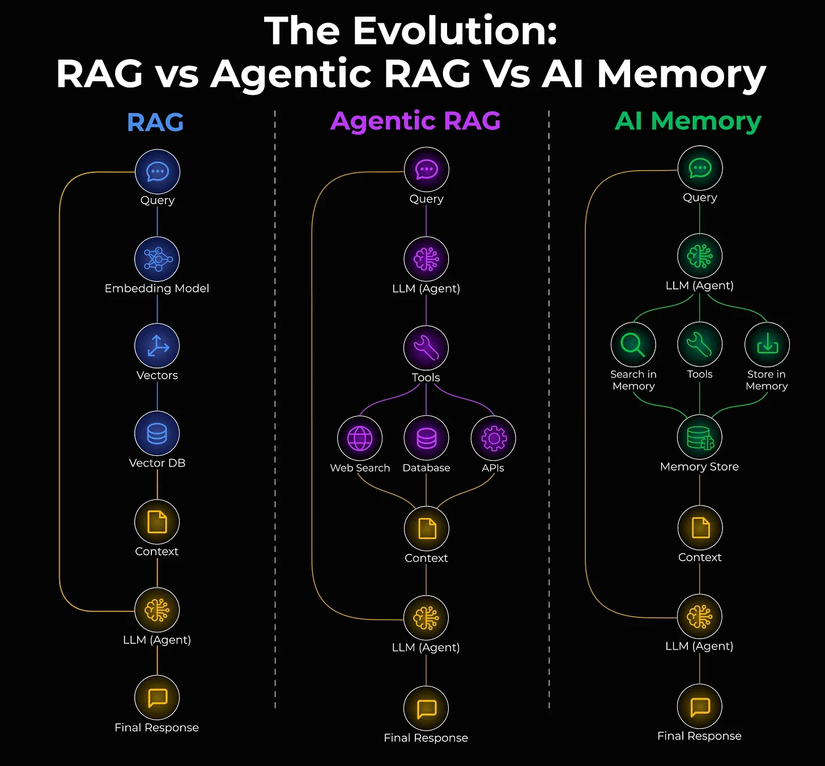
5. Truy Xuất Cơ Sở Kiến Thức (Knowledge Base Retrieval)
Hầu hết mọi người chỉ nghĩ đến RAG, nhưng RAG thực ra chỉ là một mẫu trong bức tranh lớn hơn.
Câu hỏi thực sự là: Làm thế nào để kết nối AI với toàn bộ dữ liệu của tổ chức?
Kiến thức doanh nghiệp tồn tại ở rất nhiều nơi: tài liệu, wiki, cơ sở dữ liệu, Notion, Google Drive, API, kho code…

Pipeline truy xuất bao gồm ba tầng:
- Trước truy xuất: Chiến lược chia chunk, giữ metadata, xử lý bảng biểu và dữ liệu có cấu trúc, đồng bộ hóa dữ liệu.
- Truy xuất: Sử dụng embedding model nào? Chiến lược nào (vector search hay hybrid với BM25)? Cơ chế re-ranking ra sao?
- Tăng cường: Định dạng ngữ cảnh đã truy xuất, thêm trích dẫn, xử lý mâu thuẫn…
Công cụ mã nguồn mở như Airweave giải quyết toàn bộ quy trình. Bạn chỉ cần đồng bộ một lần là có thể truy cập thống nhất từ Notion, Google Drive, cơ sở dữ liệu và nhiều nguồn khác mà không cần viết connector riêng cho từng hệ thống.
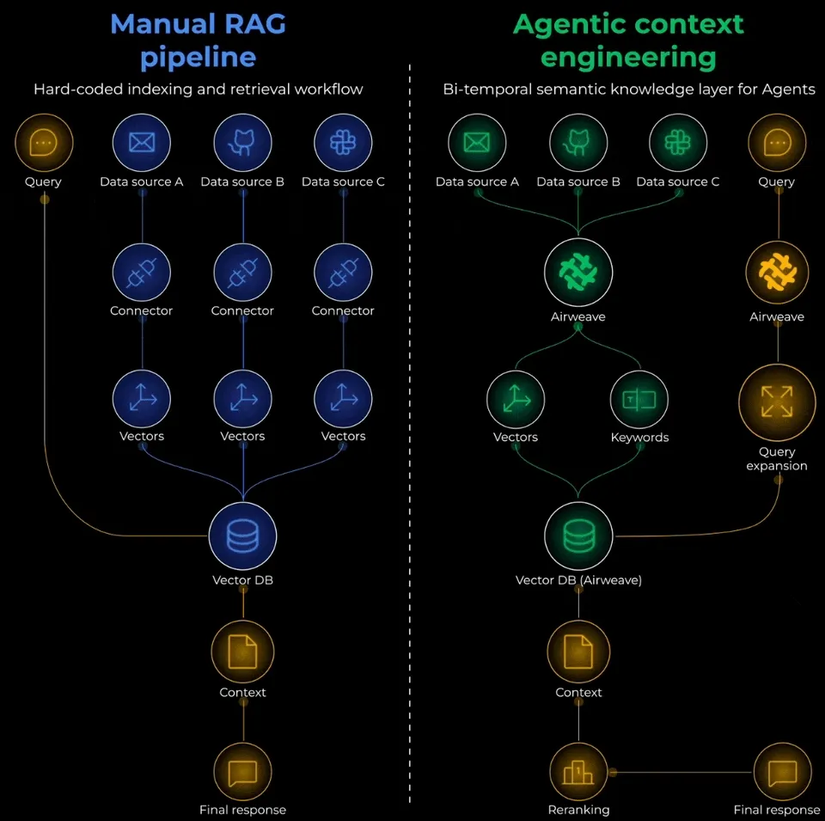
Chỉ cần tối ưu hóa cách chia chunk hoặc đồng bộ nguồn dữ liệu, bạn đã có thể cải thiện chất lượng truy xuất lên gấp 10 lần mà không cần thay đổi mô hình.
6. Công Cụ Và Agent (Tools and Agents)
Công cụ (tools) giúp mô hình vượt qua giới hạn của trọng số và cửa sổ ngữ cảnh.
Agent là thành phần quyết định khi nào và cách sử dụng các công cụ đó.
Vòng lặp cơ bản:
Truy vấn → Suy nghĩ → Hành động → Quan sát → (lặp lại đến khi đạt mục tiêu) → Phản hồi
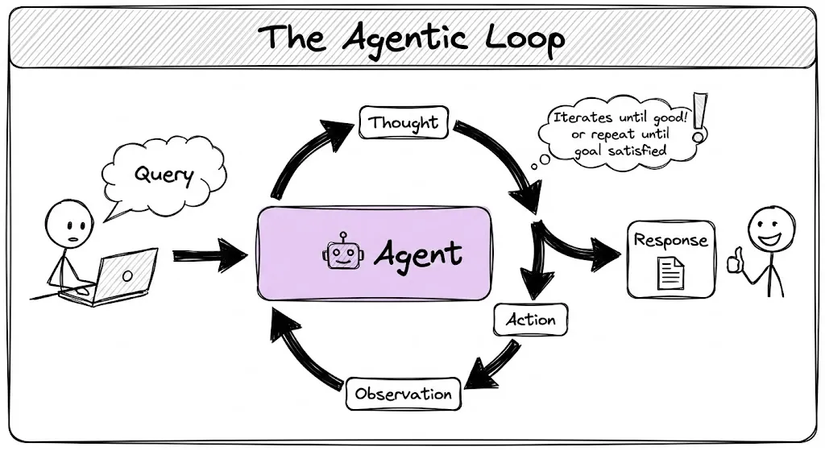
- Single-agent: Phù hợp với nhiệm vụ đơn giản (hầu hết chatbot và copilot).
- Multi-agent: Lý tưởng cho quy trình phức tạp – các agent chuyên biệt hợp tác (một agent nghiên cứu, một agent viết, một agent phê bình…).
MCPs (Model Context Protocol) đưa kiến trúc này lên tầm cao mới. Thay vì phải xây dựng N×M kết nối (3 mô hình × 4 công cụ = 12 điểm tích hợp), MCP giảm xuống chỉ còn N+M nhờ giao thức chuẩn.
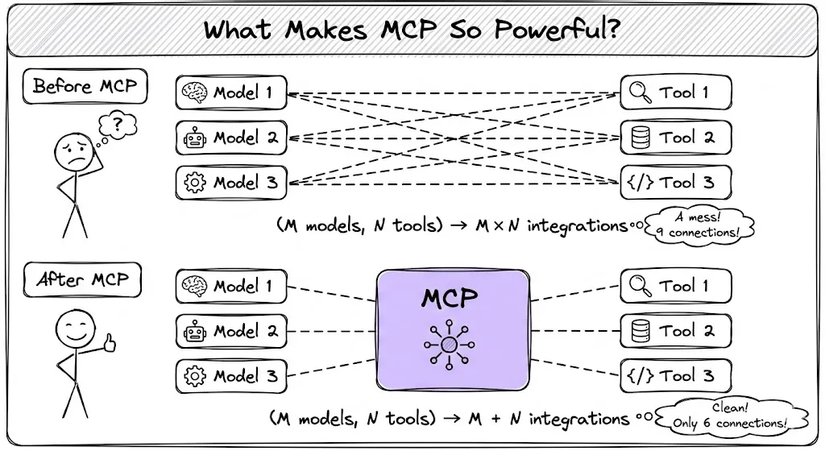
Cách đây không lâu, mọi người nghĩ rằng “prompt engineering” là chìa khóa thần kỳ.
Context Engineering đã thay đổi nhận thức đó: phép màu thực sự nằm ở toàn bộ pipeline thông tin – bạn cung cấp ngữ cảnh gì, ngữ cảnh đến từ đâu, được truy xuất và định dạng ra sao, mô hình có thể làm gì với công cụ, và nó nhớ gì qua các phiên làm việc.
Hình ảnh dưới đây tổng hợp rõ ràng cả 6 thành phần chúng ta vừa thảo luận:
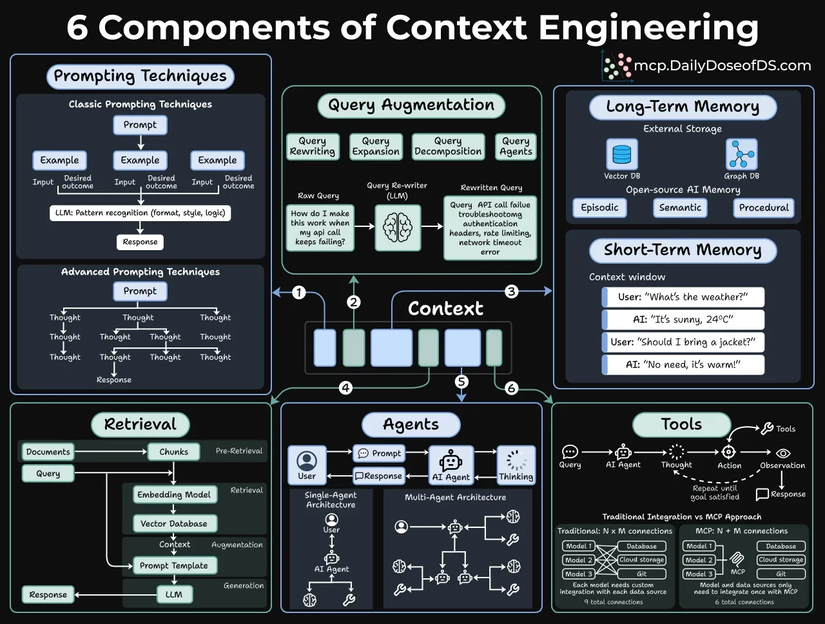
Nếu bạn đang xây dựng ứng dụng AI năm 2025–2026, đây chính là mô hình tư duy bạn cần nắm vững.
Cảm ơn bạn đã đọc!
All rights reserved
