Tại Sao Convert & Deploy Model Mới Là Phần Khó Nhất Trong Computer Vision?
Khi nhìn vào một dự án AI như hệ thống phân loại ảnh nội soi end-to-end, phần lớn mọi người sẽ tập trung vào model: nên chọn kiến trúc CNN nào, kỹ thuật fine-tune ra sao, hay độ chính xác (Accuracy) đạt được bao nhiêu phần trăm.
Nhưng nếu nhìn từ góc độ triển khai thực tế, đặc biệt là trong bối cảnh môi trường sản xuất (production) và các thiết bị biên (edge devices như mobile, camera), thì phần khó khăn nhất lại nằm ở một bước hoàn toàn khác: Đưa model từ môi trường nghiên cứu (research environment) lên chạy mượt mà trên thiết bị thật.
Hãy cùng phân tích sâu bài toán deploy model computer vision thông qua dự án phân loại ảnh nội soi thực tế dưới đây để hiểu tại sao việc huấn luyện (training) mới chỉ là khởi đầu của hành trình.
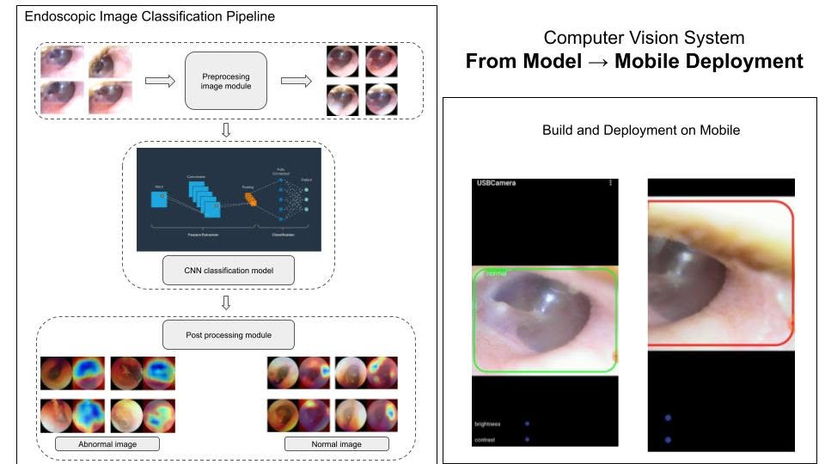
1. Khoảng cách thế hệ: Từ môi trường nghiên cứu đến thiết bị thực tế
Trong dự án phân tích ảnh nội soi này, pipeline kỹ thuật không bao giờ dừng lại ở bước nhấn nút hoàn thành huấn luyện. Sau khi sở hữu một model chất lượng (thường được viết và lưu dưới dạng PyTorch), đội ngũ kỹ sư phải đối mặt với một chuỗi chuyển đổi định dạng phức tạp:

[ PyTorch Model ] (Môi trường Research)
|
v (Export)
[ ONNX Format ]
|
v (Convert)
[ TensorFlow Model ]
|
v (Optimize)
[ TensorFlow Lite ] (Deploy lên Edge/Mobile)
Nghe qua thì quy trình này có vẻ đơn giản chỉ là "convert format" (chuyển đổi định dạng tệp). Nhưng trên thực tế, đây là một quá trình đầy rẫy những rủi ro kỹ thuật mà nếu không có kinh nghiệm thực chiến từ các khóa học AI Engineer chất lượng, bạn sẽ rất khó để tự xoay xở thành công.
2. Rủi ro kỹ thuật từ chuỗi chuyển đổi định dạng (Model Conversion)
Mỗi framework lập trình Deep Learning đều sở hữu cách định nghĩa toán tử (operators), cấu trúc tensor và đồ thị thực thi (execution graph) hoàn toàn khác nhau. Sự bất đồng bộ này tạo ra hai rào cản lớn:
2.1. Sự bất đồng bộ về toán tử giữa các Framework
Một layer hoạt động hoàn toàn bình thường trong PyTorch có thể không được hỗ trợ đầy đủ khi chuyển sang định dạng trung gian ONNX. Hoặc tệ hơn, nó bị thay đổi hành vi tính toán khi chuyển đổi tiếp sang TensorFlow.
2.2. Lỗi sai lệch đầu ra (Output Discrepancy) khó phát hiện
Điều này dẫn đến một lỗi hệ thống cực kỳ phổ biến: Model sau khi convert thành công vẫn chạy được... nhưng kết quả đầu ra (output) không còn trùng khớp với ban đầu.
Đây là điểm mù mà rất nhiều kỹ sư AI thiếu kinh nghiệm thường bỏ qua. Họ chỉ kiểm tra Accuracy trong môi trường training của Jupyter Notebook, nhưng lại quên không đối chiếu và validate lại kết quả sau từng bước convert định dạng. Kết quả là khi triển khai thực tế (deploy), hệ thống vẫn hoạt động, nhưng chất lượng dự đoán lâm sàng trên ảnh nội soi thực tế đã suy giảm đáng kể mà không một ai hay biết nguyên nhân từ đâu.
3. Thách thức tối ưu hóa tài nguyên trên thiết bị di động (Edge Device Constraints)
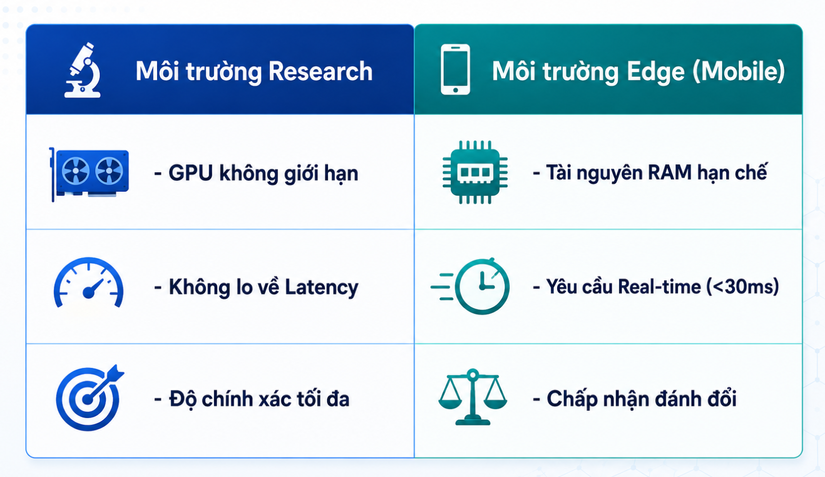
Trong khuôn khổ các đề tài nghiên cứu hoặc luận văn học thuật, model thường được huấn luyện trên các hệ thống GPU hiệu năng cao với batch size lớn, không hề bị giới hạn về bộ nhớ vật lý hay độ trễ (latency). Nhưng khi đưa hệ thống phân loại ảnh nội soi này lên ứng dụng di động của bác sĩ, mọi thứ đảo lộn hoàn toàn:
Bộ nhớ hạn chế: Các thiết bị di động chỉ có thể cấp phát một lượng RAM/VRAM rất nhỏ cho các tiến trình AI chạy ngầm.
Hiệu năng phần cứng yếu: CPU và GPU tích hợp trên điện thoại có năng lực tính toán kém xa các dòng card chuyên dụng như NVIDIA A100 hay H100.
Yêu cầu khắt khe về thời gian thực (Real-time inference): Bác sĩ nội soi cần kết quả phân tích hiển thị ngay lập tức khi camera quét qua tổn thương, yêu cầu độ trễ phải cực kỳ thấp.
Nghệ thuật "đánh đổi" (Trade-off) bằng Quantization và Pruning
Tình thế bắt buộc chúng ta phải bước vào bài toán đánh đổi. Để giảm kích thước file model và tăng tốc độ xử lý, các kỹ sư phải áp dụng các kỹ thuật tối ưu hóa đồ thị nâng cao:
Quantization (Lượng tử hóa): Giảm độ chính xác của các trọng số từ số thực dấu phẩy động Float32 xuống số nguyên Int8
Pruning (Cắt tỉa): Loại bỏ bớt các trọng số hoặc các kết nối nơ-ron không quan trọng để thu nhỏ mô hình.
Tuy nhiên, mỗi bước tối ưu hóa toán học này đều có nguy cơ làm sụt giảm độ chính xác của mô hình ban đầu. Lúc này, công việc của bạn không còn là đi tìm một "model tốt nhất trên lý thuyết", mà là tìm ra một "model phù hợp nhất với hạ tầng thiết bị vật lý".
4. Tích hợp hệ thống (System Integration) - Mảnh ghép cuối cùng của Pipeline
Deployment trên thiết bị di động không đơn thuần chỉ là câu chuyện ném file model vào ứng dụng. Đó là cả một bài toán lớn về tích hợp hệ thống (System Integration).
Model AI cần được tích hợp sâu vào mã nguồn ứng dụng Android/iOS, kết nối trơn tru với pipeline xử lý dữ liệu đầu vào (hình ảnh trực tiếp từ camera nội soi hoặc từ thư viện ảnh), và trả kết quả để kích hoạt các logic nghiệp vụ phía sau.

Nếu quá trình xử lý tiền kỳ (preprocessing) trên thiết bị di động không đồng nhất tuyệt đối với preprocessing lúc huấn luyện (ví dụ: chuẩn hóa ảnh - normalize sai tỉ lệ, hoặc resize kích thước khác biệt), thì dù model có tốt đến đâu, kết quả trả ra vẫn hoàn toàn sai lệch.
Do đó, một hệ thống AI thực chiến vững chắc đòi hỏi sự kết hợp nhuần nhuyễn giữa kỹ năng phát triển phần mềm và kỹ thuật xử lý dữ liệu. Để xây dựng được các pipeline luân chuyển dữ liệu từ thô sang tinh một cách tự động và ổn định, việc trang bị kiến thức từ một khóa học Data Engineer chuyên nghiệp sẽ là bệ phóng vững chắc giúp bạn làm chủ luồng đi của dữ liệu trước khi nạp vào model.
5. Chìa khóa để thu hẹp khoảng cách từ Model đến Production
Từ góc nhìn của một kỹ sư AI thực chiến, dự án phân loại ảnh nội soi này phản ánh rất rõ một sự thật hiển nhiên trong ngành công nghiệp phần mềm hiện nay: Khoảng cách giữa việc "train được một model" và "deploy thành công một hệ thống AI" là một khoảng trống cực kỳ lớn.
Hầu hết giá trị thực tiễn mang lại cho doanh nghiệp không nằm ở việc bạn hiểu sâu sắc bao nhiêu thuật toán CNN hay Transformer trên giấy tờ, mà nằm ở việc bạn có đủ năng lực đưa hệ thống đó ra ngoài thực tế một cách ổn định, có thể đo lường, giám sát và mở rộng quy mô (scale) một cách dễ dàng hay không.
Nếu bạn chỉ dừng lại ở bước train model, bạn mới chỉ đi được khoảng chặng đường của một dự án AI. Một nửa chặng đường quan trọng còn lại — bao gồm convert, optimize, deploy và đảm bảo hệ thống hoạt động chính xác trong môi trường thực — chính là những gì các doanh nghiệp đang đỏ mắt tìm kiếm ở các ứng viên MLOps hiện nay.
Lời kết
Nếu bạn muốn bứt phá giới hạn bản thân, tự tay thiết kế và vận hành trọn vẹn vòng đời của một sản phẩm AI từ khâu xử lý dữ liệu thô, huấn luyện cho đến khi deploy thành công lên thiết bị thật:
Tham khảo ngay Khóa học AI Engineer chuẩn quốc tế để làm chủ kỹ năng MLOps, kỹ thuật tối ưu hóa model và quy trình deploy thực chiến nhất trên thị trường.
Đồng thời, tham gia Khóa học Data Engineer thực chiến để xây dựng tư duy nền tảng vững chắc về thiết kế pipeline, tối ưu hóa cơ sở dữ liệu lớn phục vụ cho các ứng dụng AI thời gian thực.
Hãy đi trọn vẹn hành trình 100% của một dự án AI thay vì dừng chân ở vạch xuất phát huấn luyện!
All rights reserved
